
Ak ste niekedy skúšali previesť v Data Studiu hodnotu metriky na dimenziu, pravdepodobne ste boli poctený chybovou hláškou: „Only numeric literals are allowed if aggregated fields are used in CASE„. Čo sa s tým dá robiť? Je vôbec možné vytvoriť textovú dimenziu z číselnej metriky? A ak áno, aké to má úskalia? Pozrieme sa na to v ďalšom článku na želanie.

V tomto modelovom príklade použijeme dáta z Google Search Console. Pre každú query priradíme číselnú hodnotu metriky Position Group (metric) aj textovú hodnotu dimenzie Position Group (dimension).
Vytvorenie vlastnej metriky Position Group (metric)
Pre vytvorenie vlastnej metriky použijeme funkciu CASE. V tomto prípade som zvolil rozdelenie queries do šiestich skupín. Samozrejme, rozdelenie je na vás. Na vstupe je priemerná pozícia zo Search Console, na výstupe zástupná hodnota pre tú ktorú skupinu.
CASE
WHEN Average Position = 1 THEN 1
WHEN Average Position <= 3 THEN 3
WHEN Average Position <= 10 THEN 10
WHEN Average Position <= 20 THEN 20
WHEN Average Position <= 30 THEN 30
ELSE 999
END
Vytvorenie vlastnej metriky Position Group (dimension)
Podobne vytvoríme aj vlastnú dimenziu, tu je však potrebné previesť číselnú hodnotu na reťazec znakov. Na to použijeme funkciu CAST(). Funkcia CASE bude mať potom tvar:
CASE
WHEN CAST(Position Group (metric) AS TEXT) = „1“ THEN „First position“
WHEN CAST(Position Group (metric) AS TEXT) = „3“ THEN „Top 3“
WHEN CAST(Position Group (metric) AS TEXT) = „10“ THEN „Top 10“
WHEN CAST(Position Group (metric) AS TEXT) = „20“ THEN „Top 20“
WHEN CAST(Position Group (metric) AS TEXT) = „30“ THEN „Top 30“
ELSE „Other positions“
END
Týmito dvoma jednoduchými funkciami sme vytvorili vlastnú metriku aj vlastnú dimenziu, ktoré nám rozdelia queries do skupín, resp. levelov podľa hodnoty priemernej pozície.
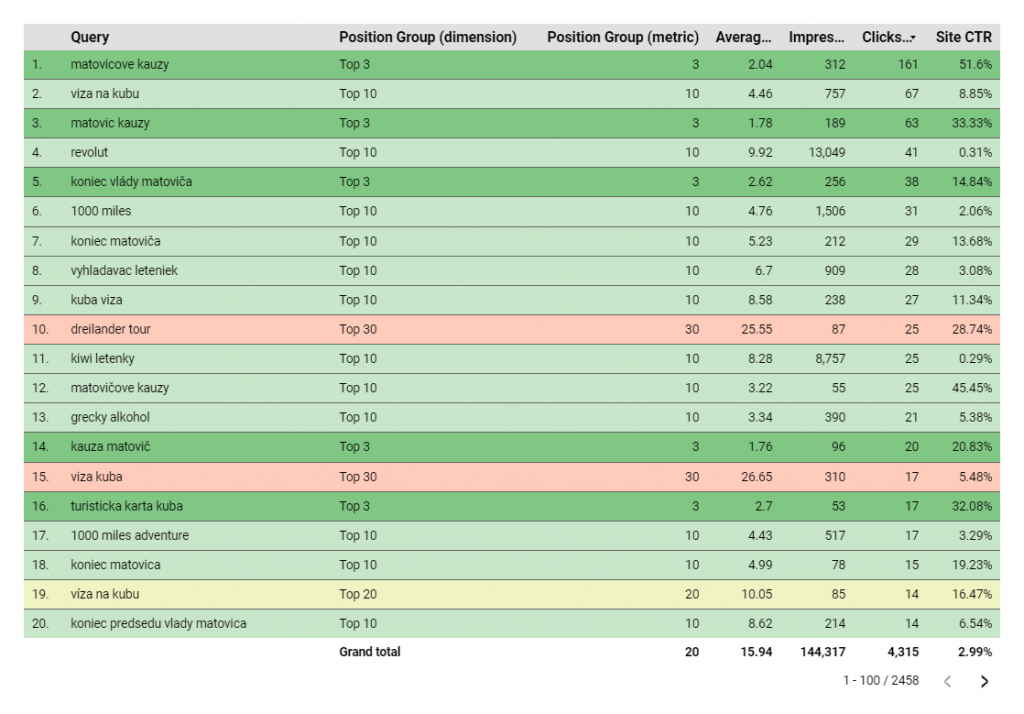
Výsledná tabuľka môže vyzerať napríklad takto:
Výhody a nevýhody vytvárania vlastných polí z agregovaných dát
Medzi výhody takéhoto riešenia patrí určite prehľadnosť reportu Už pri prvom pohľade môžete veľmi ľahko identifikovať, ktoré queries sa nachádzali v ktorej skupine bez pohľadu na hodnotu priemernej pozície. Vylepšiť to môžete aj podfarbením riadkov ako som to urobil vo vzorovej tabuľke.
Naopak, medzi najväčie nevýhody patrí to, že je to len akási pseudo-dimenzia. Nie je možné nastaviť filtrovanie podľa tejto hodnoty, keďže hodnota dimenzie vychádza z agregovaných dát. Vo filtri by ste teda mali len jednu priemernú hodnotu pre všetky queries.